论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks
摘要

问题引入
我们先回顾一下 R-CNN 的基本步骤:
1. 使用 seletive search 从输入图片中提取大约 2k 个候选区域。
2. 对所有候选区域进行 warp 到固定尺度(227 × 227),也就是使得不同尺度和长宽比的区域被变换到相同大小,然后将其送入 CNN 网络,提取出 feature maps 。
3. 使用 SVM 进行分类,并做边框回归。
我们再来看一张时间复杂度上的统计分析图

由图可看,除了CNN网络提取特征耗时(需要对每一张图片的2000个窗口进行卷积网络计算),其中的warp操作(Cropping & resizing )也是挺费时间的。
另外我们从下图进行分析warp这种操作对信息可能造成的影响:

在左图中,我们进行裁剪 (crop) 的时候,丢失了车头和车尾信息,后续再送入 CNN 网络提取特征必定对识别精度有影响。
在右图中,进行 warp 操作后,明显可以看到塔已经变形。
我们不禁要问,既然 warp/crop 操作既费时间,又会造成信息损失或破坏,那么我们为什么要进行warp/crop这类操作?
答案是:CNN 网络对输入有固定尺度要求,我们需要 warp 来将输入统一到一个尺度。
进一步地,为什么 CNN 要求输入图片具有统一的尺寸呢?
事实上一个 CNN 网络主要包含卷积层和紧随其后的全连接层,而卷积层能允许任意大小的图像输入网络,并且产生任意大小的 feature maps, 只有全连接层对尺寸有限制要求,因为全连接层的计算相当于输入的 feature maps 数据矩阵和全连接层权值矩阵进行内积,全连接层的参数维度在配置一个网络时就已经是固定下来了,所以要使两个矩阵能进行内积,那么输入的 feature maps 的数据矩阵维数也需要固定。
很自然的,我们会想有什么办法能使得无论什么 size 的 feature maps 从卷积层出来经过变换后都能变成统一维度的特征向量,然后送入全连接层,这样就能去掉之前的warp操作。
论文的作者们提出了一种空间金字塔池化(SPP)的办法来将不同大小的 feature maps 归一化到相同维度。
算法流程

如上图所示,在CNN的最后一个卷积层之后,加入一个 SPP 层(空间金字塔池化),得到一个固定长度的特征向量,再传给后面的全连层。
那么重点来了,SPP具体是怎么样将不同尺度 feature maps 归一化到相同维度的呢?
还是拿图说话:

根据论文,在Conv5是最后一个卷积层,共有有256个 filter,因此输出之后有256个 feature map,如图所示,无论feature map 的size 有多大,都对每个 feature map 分别进行 1×1、 2×2、4×4 的网格划分,并对其中每个小块进行最大池化(max pooling), 这样最后特征向量的维度都变成( 1 + 4 + 16) * 256 ,也就是 21 × 256维,这个特征向量的维度是固定的。更进一步地,假设如果最后一个卷积层有k个filter,也就是产生k个feature map, SPP 有 M 个 bins, 那经过SPP得到的是一个kM维的向量,之后再将其送入后面的全连接层。

R-CNN VS SPP-net
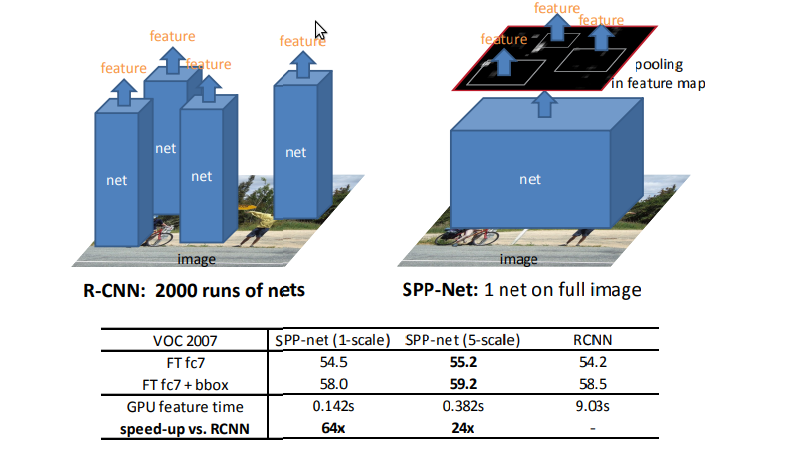
对比 R-CNN, SPP-net 步骤为:
1. 用 EdgeBoxes 算法从输入原图中生成候选窗口。在论文中,作者指出:在 CPU 上 ,Selective Search (SS) 对每张图片提取 proposal 需要 1到2 秒,而 EdgeBoxes 方法只需要大约 0.2s.
2. 利用 SPP-net 网络结构。与R-CNN相差最大,把整张待检测的图片,输入 CNN 中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。与之相比,R-CNN 输入的是每个候选框,然后再进入 CNN ,因为 SPP-net 只需要对整张图片进行一次特征提取,速度会大大提升。
3. 和 R-CNN 一样,采用SVM算法进行对特征向量分类识别,最后边框回归进行位置修正。
结果
在 ILSVRC 2014 比赛中,论文作者采用 SPP-net 方法在38个队伍中获得了目标检测第二和图像分类第三的好成绩。


结论
SPP-net 将空间金字塔池化引入 CNN , 从此不再需要固定图像输入尺寸,减少了冗余计算,提高了处理输入图片的速度,而且对于目标检测任务来说,与 R-CNN 相比,由于其保留了更多的特征,检测精度也有相应地提高。
但是缺点也不少:
1. 训练分为多个阶段,步骤繁琐。(论文中指出要先进行single size 训练,然后再进行 Multi-size 训练)。
2. 由前面可知,最后一个卷积层不能改变,因此在 fine tuning 时固定了卷积层,只对全连接层进行微调,然而对于一个新的任务,有必要对卷积层也进行微调。
参考链接
Spatial Pyramid Pooling in Deep Convolutional Networks》
https://blog.csdn.net/xjz18298268521/article/details/52681966
笔者目前主要从事自动驾驶研发工作,本公众号主要关注机器人和自动驾驶方向的技术以及最新进展,闲暇时也和大家聊聊读书、生活以及最新的电子科技产品,希望大家喜欢,共同进步!